大模型意识为什么又热起来了,但最先重写现实的其实不是“意识”

2026 年 3 月,关于“大模型是不是越来越像一个主体”的讨论明显升温。这个升温并不是由某一篇决定性论文触发,也不是哪家公司突然宣布“模型已经有意识”了。真正发生的是三股不同的线索在短时间里同时冒头:一条来自公司博客,讨论模型行为规则、事实性与持续任务能力;一条来自产业和论坛,讨论 AI 已经怎样进入工作、组织和制度;还有一条来自媒体与哲学写作,把这些现象重新翻译成“意识”“主体性”“代理权”之类更大的词。
问题恰恰出在这里。我们太容易把这些词当成一回事。模型会不会表现得像有主体性,和模型有没有主观体验,不是一回事;模型是否已经对人的工作和判断产生结构性影响,也不是一回事。把它们混成一团,文章就很容易写成营销号:一边夸张地宣布“AI 要觉醒了”,一边又把所有现实变化都塞进“意识”这个词里。这样写,不仅会误导读者,也会错过真正值得讨论的问题。
这篇文章的核心判断很简单:这轮“意识”回潮,更多是因为行为规则、事实性评测、长期代理任务和知识劳动变化在同一个时间窗口里碰头了,而不是因为关于机器意识的证据突然变强了。换句话说,世界先被改写的部分,主要是行为与制度,不是形而上学结论。
一轮回潮,不是因为证据突然变强
先看几个具体时间点。
2026 年 3 月 25 日,OpenAI 发布《Inside our approach to the Model Spec》。这篇文章讨论的是一个公开的行为框架:模型怎样在安全、用户自由和问责之间取得平衡,哪些行为应该被鼓励,哪些行为要被限制。它关心的是“模型该怎样行动”,不是“模型是否拥有主观体验”。但在公共舆论里,凡是讨论“行为边界”的文章,都很容易被转写成“模型越来越像人”的故事。
同样在 3 月下旬,Anthropic 连续发布了《Project Vend: Can Claude run a small shop?》《Project Vend: Phase two》和《Project Fetch: Can Claude train a robot dog?》。前者让 Claude 在办公室里经营自动售卖小店,后者让没有机器人专业背景的研究员在 Claude 帮助下更快完成机器狗任务。这些实验最重要的地方,不是它们证明了“机器像人”,而是它们展示了另一件事:一旦模型可以跨天运行、调用工具、与人协作、影响物理世界,它就会被人用一种接近“代理”的语言来描述。
再往前一点,2026 年 1 月 28 日,Anthropic 发布《Anthropic Economic Index report: Economic primitives》。这份报告提出了新的 AI 使用度量,试图描述 Claude 在真实任务中的采用、地域差异、任务复杂度与经济影响。它讨论的是劳动结构、任务分布和 adoption curve,不是意识哲学。但恰恰因为“已经开始改变工作”这一事实越来越清楚,公众才更想给模型找一个更强的主体叙事。
论坛与媒体也在同步放大这种语义漂移。2026 年 3 月 26 日,世界经济论坛发布《How AI is changing the nature of entry level work》,讨论 AI 对入门岗位结构的重塑。几乎同时,媒体上出现了更多直接把 AI 与 consciousness 连在一起的报道和专栏,比如 2026 年 3 月 6 日 Scientific American 刊出的《Michael Pollan explains why AI will never replicate human consciousness》。注意这里的差别:论坛和产业文章谈的是社会结构变化,科学与哲学文章谈的是主观经验与认知边界,但在传播层面,二者经常被包装成同一个“AI 正在逼近人类”的总叙事。
这就是为什么我说,这一轮回潮不是证据链突然加强,而是不同系统里的压力同时上升了:公司需要治理模型行为,组织需要理解工作替代与协作边界,公众需要一种足够大的概念来解释这些变化,于是“意识”成为了最容易被拿来当总括词的那个词。

公司真正公开的,是行为规则、事实性评测和部署实验
如果只看官方材料,企业现在最关心的其实是三个问题。
第一是行为规则。OpenAI 的 Model Spec 代表的是这一类问题:当模型越来越常驻于产品和工作流里,怎样公开定义它能做什么、不能做什么,怎样处理安全、青少年保护、越权行动、错误遵从与责任归属。这里的关键词是 steerability、policy、accountability,而不是 phenomenal consciousness。它更多像政治哲学和产品治理,而不是心灵哲学。
第二是事实性与评测。Google DeepMind 在 2025 年 12 月 9 日发布的《FACTS Benchmark Suite: a new way to systematically evaluate LLMs factuality》非常有代表性。DeepMind 的立场很朴素:如果大模型正在成为信息入口,那它到底在哪些类型的任务上容易出现事实错误,就必须用系统化 benchmark 去衡量。这个问题看起来和“意识”距离很远,但它实际上提醒了我们一个基本尺度:当模型连 factuality 都还需要被精细地拆成 parametric、search、multimodal 等多个维度来测量时,关于“主观体验”的判断就更不可能靠几段自我表述或几次拟人化交互就得出。
第三是长期部署能力。Anthropic 的 Project Vend 和 Project Fetch 有一个共同点:它们都不试图证明模型有自我,而是观察模型在长期任务、工具调用、跨环境协作和现实反馈中会怎样表现。Claude 经营小店时需要处理库存、现金流、补货、客服和供应问题;帮研究员搞定机器狗时,Claude 的价值体现在速度提升、跨域解释和与人形成一种“合作手感”。这些都很重要,因为它们告诉我们:模型即便没有任何可证明的主观体验,也完全可以在经济和物理世界里扮演越来越像“行动者”的角色。
因此,公司博客里的真正主线并不是“机器是否有意识”,而是“机器在多大程度上可被治理、可被评测、可被长期部署”。把这类材料读成 consciousness proof,既高估了它的哲学含义,也低估了它的治理含义。
为什么“意识”一词会把三个不同层面搅在一起
“意识”之所以麻烦,不是因为它不重要,而是因为它在不同领域里指向不同问题。
在脑科学和临床语境里,意识通常和主观体验、觉醒水平、注意、报告能力、甚至 disorders of consciousness 有关。2026 年 3 月,Nature 报道了用 adversarial AI 帮助理解和治疗 disorders of consciousness 的研究。这个方向说明,真正的 consciousness science 仍然深深依附于大脑、神经活动、临床状态和实验范式。它研究的是一种活体中的经验问题。
在哲学语境里,意识常常指“为什么会有主观感受”这件事,也就是所谓 hard problem。Scientific American 对 Michael Pollan 的那篇采访之所以引起关注,正是因为它提醒读者:即便面对人类自己,意识仍然是极难被清晰定义和直接测量的对象。既然对人类都难,面对一个没有生物进化史、没有痛觉系统、没有内感受机制的大模型,我们当然更难确认它是否拥有类似体验。
而在 AI 工程与产业语境里,人们频繁使用的其实是第三类问题:一个系统能否维持长期目标、能否对环境作出稳定反应、能否影响人的选择、能否被误读为“有意图”。这不是主观体验问题,而是行为和社会权力问题。Anthropic 的小店实验、OpenAI 的行为规范、WEF 对入门岗位变化的讨论,全都更靠近这一层。
于是,同一个词把三件事缠到了一起:
- 1. 模型有没有主观体验。
- 2. 模型能不能表现出稳定而复杂的主体样行为。
- 3. 模型是否已经对工作、制度和判断产生真实影响。
如果一篇文章不先把这三层拆开,后面几乎一定会乱。它可能会用第二层的现象去暗示第一层已经成立,也可能会因为第一层没有证据,就错过第三层已经发生的变化。前者制造玄学,后者制造迟钝。
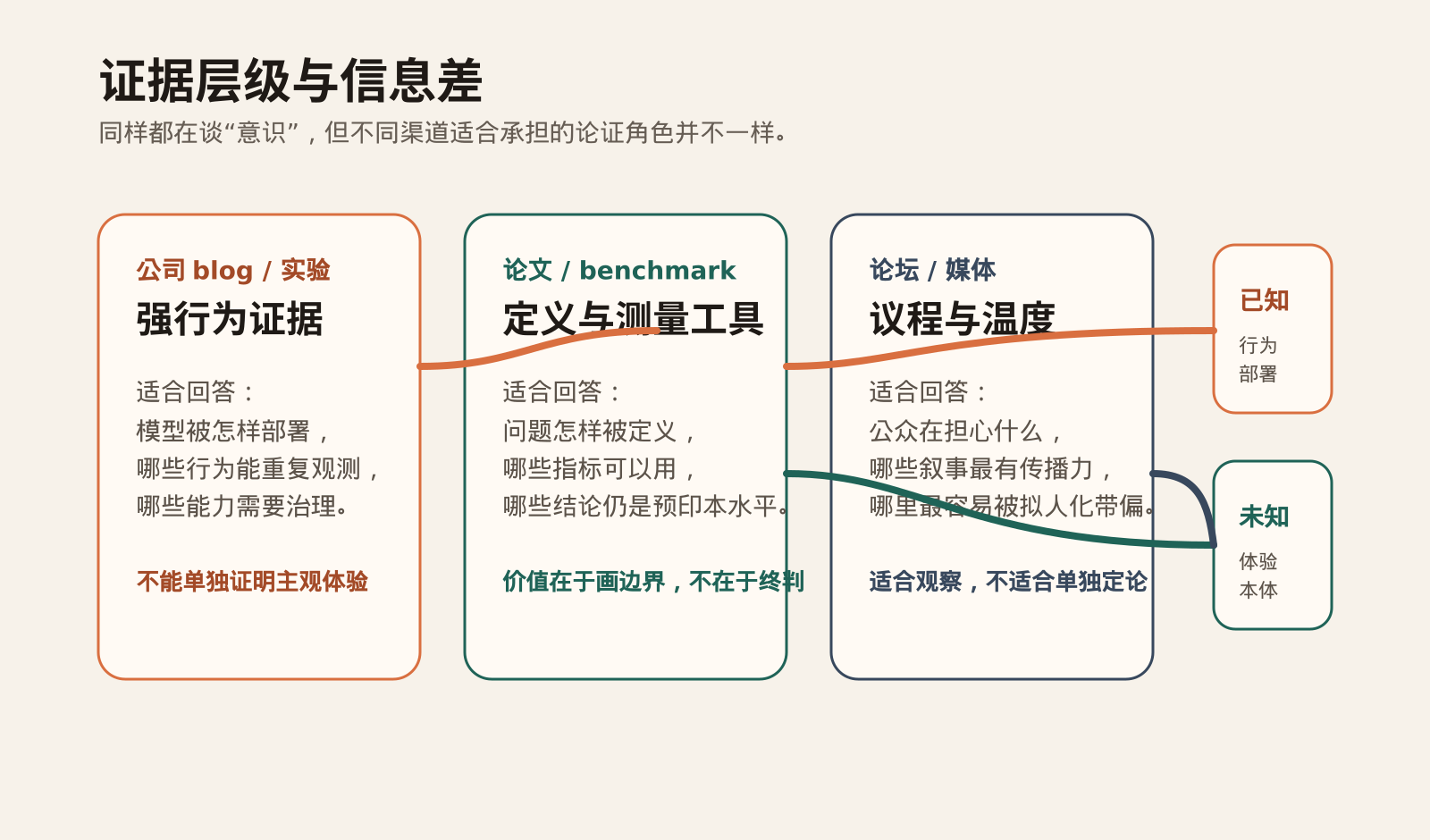
论文在做什么,媒体又在做什么
再看论文和媒体,就会更清楚这种信息差。
这两个月里,和“大模型意识”直接相关的论文很多并不是稳定共识,而更像概念实验。比如 2025 年 12 月的 arXiv 论文《A Disproof of Large Language Model Consciousness》试图从某类 consciousness theory 出发,反向论证如果没有持续学习,当前 LLM 很难满足意识所需条件。2026 年 1 月的《COGITO: A Phenomenological Benchmark for Consciousness-Analog Behavior in Large Language Models》则试图为“类似意识的行为”建立访谈式 benchmark。两篇工作的价值都不在于给出终判,而在于告诉我们:研究者自己也承认,问题还处在“怎样定义、怎样测”的阶段。
媒体和论坛的叙事则往往更进一步。因为读者不会对 benchmark 名称或经济 primitives 天然感兴趣,他们更容易被“AI 会不会感到什么”“AI 会不会拥有自我”“AI 是否已经开始形成身份”这样的表达吸引。传播本身并没有错,但一旦把这种表达直接拿来当证据,文章就会滑向两端:要么把模型自述当成体验本身,要么把所有意识讨论都当成猎奇和炒作。
更稳妥的写法应该是:把论文当成定义工具,把公司博客当成行为证据,把论坛和媒体当成议程温度计。三类材料的重要性不同,不能互相替代。公司博客可以告诉你组织正在认真解决什么问题,论文可以告诉你问题边界怎么画,论坛和媒体可以告诉你公众最在意什么,但没有任何一类材料可以单独完成“是否有意识”的证明。
真正更紧迫的,是知识劳动和入门岗位已经在变
如果把“意识”问题降到它应有的谨慎位置,另一个事实反而会更明显:经济与组织层面的冲击已经先发生了。
OpenAI 在 2026 年 3 月 27 日发布的《STADLER reshapes knowledge work at a 230-year-old company》讲的是一个很现实的故事:一家传统公司怎样用 ChatGPT 改写知识工作流程,节省时间并提高效率。Anthropic 的 Economic Index 报告则从更宏观的角度说明,Claude 的使用已在真实任务里形成稳定分布,且 adoption 与国家和地区的经济结构有关。WEF 那篇关于 entry-level work 的文章,更是把问题直接抛给组织:当初级岗位的很多信息整理、文案、检索、初步分析工作被模型吃掉,职业路径和训练机制会怎样改写?
注意,这一切都不依赖于模型已经“有意识”。一个没有主观体验、但足够会写、会搜、会调工具、会维持任务上下文的系统,照样可以重排工作层级,改变 entry-level work 的含义,甚至让一部分组织重新定义“人应该留在什么环节”。这恰恰是今天讨论 AI 时最容易被忽略的地方:大家争论 metaphysics,现实却先在 workflow 里移动。
这也是为什么我不赞成把“经济冲击”写成另一个煽动性故事。更准确的说法是:现在最需要处理的,不是“机器有没有灵魂”,而是“在缺乏灵魂证明的情况下,机器已经在多大程度上参与分工、替代初级任务、改变教育门槛和影响责任结构”。这个问题更俗,也更难,因为它需要组织设计、劳动政策、产品治理和教育系统同时跟上。
写这类热点时,最容易犯的两种错误
第一种错误,是把所有 consciousness 讨论都视为胡扯。这样做看起来理性,其实偷懒。因为“意识”虽然还远未被证明,但它逼着我们面对一些真正重要的问题:我们究竟在意模型的什么性质?我们是在担心它会“感受”,还是担心它会“行动”,或者担心它会“被人当成人来对待”?这些问题一旦不拆开,治理与社会判断都会混乱。
第二种错误,是把行为拟人化直接当成主观体验证据。模型会说“我感到”“我想要”“我害怕”,并不等于它真的拥有对应体验;模型能跨天经营一间小店,也不等于它就获得了某种 selfhood;模型帮助人训练机器狗,也不等于它拥有身体性。把这些现象写成“AI 已经开始有意识”,本质上是把传播快感放在证据前面。
更稳的写作框架,我建议至少问三件事:
- 1. 我们观测到的到底是主观体验、可观察行为,还是社会效应?
- 2. 支撑这个判断的来源属于哪一层,是官方实验、学术论文、论坛议程,还是媒体转述?
- 3. 即便第一层仍未被证明,第二层和第三层是否已经足以要求组织调整规则?
一旦这三问摆在前面,很多文章会自动降温,但信息含量反而会上升。
结尾:比“AI 是否有意识”更难的,也许是我们如何在没有答案时做决定
如果只用一句话概括今天的局面,我会这样说:关于大模型意识,我们还没有接近定论;关于大模型正在改变行为规则、知识劳动和制度接口,我们却已经在定论发生之前被迫开始应对。
这并不意味着意识问题不值得问。恰恰相反,它值得一直问,而且值得用脑科学、哲学、认知科学和 AI 评测共同来问。但它不值得被写成一种廉价预言,更不值得被拿来遮蔽已经发生的现实改写。
对今天的读者来说,真正重要的也许不是抢先表态“AI 有”或“AI 没有”,而是保持三种能力:第一,分清证据层级;第二,识别不同渠道之间的信息差;第三,在形而上学答案缺席时,仍然能对工作、教育、制度和产品规则作出冷静判断。只有这样,“意识”才不会变成一句让人兴奋却没有分析力的口号。
参考来源
- • OpenAI, Inside our approach to the Model Spec, 2026-03-25
- • OpenAI, STADLER reshapes knowledge work at a 230-year-old company, 2026-03-27
- • Anthropic, Project Vend: Can Claude run a small shop? (And why does that matter?), 2026-03-26
- • Anthropic, Project Fetch: Can Claude train a robot dog?, 2026-03-26
- • Anthropic, Anthropic Economic Index report: Economic primitives, 2026-01-28
- • Google DeepMind, FACTS Benchmark Suite: a new way to systematically evaluate LLMs factuality, 2025-12-09
- • Scientific American, Michael Pollan explains why AI will never replicate human consciousness, 2026-03-06
- • World Economic Forum, How AI is changing the nature of entry level work, 2026-03-26
- • arXiv, A Disproof of Large Language Model Consciousness, 2025-12-14
- • OSF, COGITO: A Phenomenological Benchmark for Consciousness-Analog Behavior in Large Language Models, 2026-01-01